1. 目标定位
我们首先研究一个简单的定位分类问题,通常只有一个较大的对象位于图片中间位置,我们对他进行定位和识别。
首先描述我们的分类问题,分类结果为行人、汽车、摩托车、背景。背景意味着不含前三类。
然后加上定位,我们可以输出红色方框的中心点、高度、宽度。
根据上述分类与定位逻辑,采用监督学习的方法,标签定义为:

如上图所示,p_c表示是否有行人、汽车、摩托车,当p_c=0时,代表只是背景,p_c=1表示有三种中的一种。(b_x,b_y)表示方框的中心点,b_h表示方框的高,b_w表示方框的宽,c_1、c_2、c_3分别代表三种类别中的一种。
当p_c=0时,其他的值毫无意义。
然后看一下损失函数:
当y_1=1时:
\[L(\hat y,y)=(\hat y_1 -y_1)^2+(\hat y_2-y_2)^2+\ldots+(\hat y_8-y_8)^2 \tag{1-1}\]当y_1=0时:
\[L(\hat y,y)=(\hat y_1 -y_1)^2 \tag{1-2}\]通过公式1-1与1-2所示,我们使用了平方误差的方法表示损失函数。
以上就是使用神经网络解决目标定位与目标分类问题的过程,相当于在普通图像分类的基础上,增加了目标定位。
了解了这个过程,我们再来看更复杂的逻辑。
2. 基于滑动窗口的目标检测
首先我们需要训练出一个目标二分类网络,比如汽车,我们的网络要能够判断图像中是否有车。
其中训练数据由手动裁剪后的汽车图片所训练,就是一张图片几乎被一个汽车所占据,卷积网络输出0代表是汽车,输出1代表不是汽车。
然后通过我们训练的卷积神经网络去检测目标。

方法为首先选定一个特定大小的窗口,然后根据窗口内的图像,使用卷积神经网络进行预测,即判断窗口内有没有车。窗口依次处理第二个位置的图像,直至遍历完成。
这就是图像滑动窗口操作。
如果遍历完成后,并没有发现汽车,则使用更大一点的窗口重复上述过程,直至检测到。

当然,上述基于滑动窗口的目标检测存在很大的缺点,就是计算成本高,卷积网络要处理一个个的小方框。
3. 滑动窗口的卷积实现
为了在卷积层上实现滑动窗口的操作,我们首先要讲网络的全连接层改造为卷积层,下面来看具体方法:
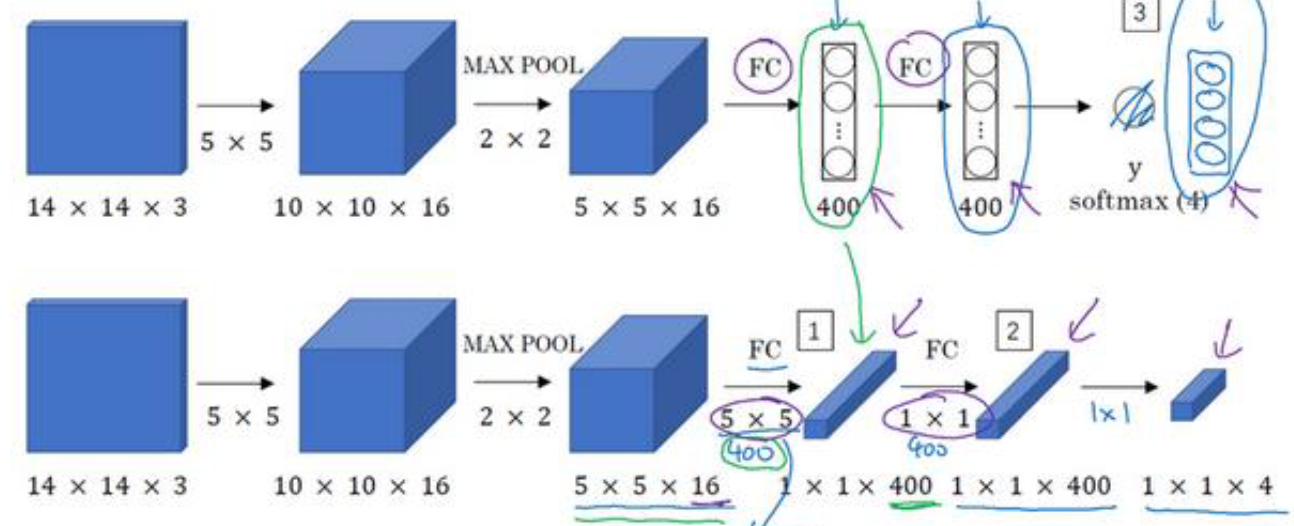
我们来看一下上述图片,上面一层是正常的网络,结构为:$CONV \rightarrow POOL \rightarrow FC \rightarrow FC \rightarrow FC$,将其转化为对应的卷积层为下面一层图所示,前面conv层与pool层不变,将后面的全连接层转换为CONV层,其中FC层中的单元数改造为CONV层中的通道数量。
上述过程就是将FC层改造为CONV层的操作,最终获得 1 \times 1 \times 4维度的矩阵。
改造网络之后,我们看一下如何实现滑动窗口:
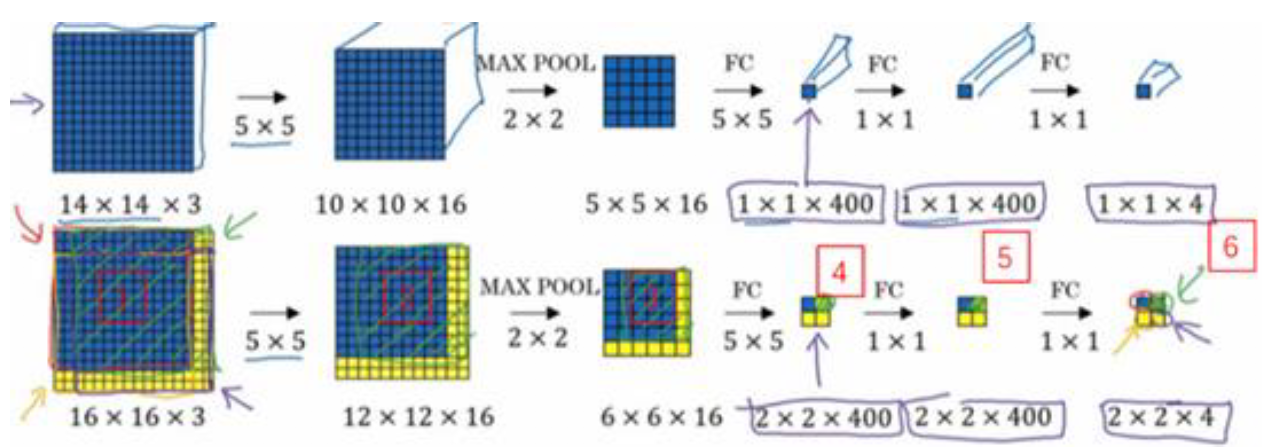
如上图所示,上半部分为我们将FC改造为CONV之后的网络结构,最终得到1 \times 1 \times 4维度的结果。
实现滑动窗口的操作很简单,如下半部分所示,我们不改变网络结构,直接将完整的图像16 \times 16 \times 3输入当前网络中,经过每一步的处理,得到 2 \times 2 \times 4的矩阵,通过图片,我们知道其对应着在完整的图像上实现了四次滑动窗口,相当于将每个窗口并行预测值。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算。
上面就是在卷积层上实现滑动窗口的内容,提高了整个算法的效率,但是有一个缺点,就是边界框的位置不够准确,因为在固定的网络下,我们的窗口大小是固定的,且是正方形,而且窗口是离散的。
4. Bounding Box预测
使用卷积层实现滑动窗口之上,边界框的位置不够准确,我们来使用更精确的边界框。
其中一个能得到更精准边界框的算法是YOLO(You only look once)算法,它的思想是将第1小节与第3小节的内容结合起来,我们来具体看一下:
yolo算法的做法是将一个原始图片分成n \times n的网络,我们取$3 \times 3$,基本思想是使用图像分类与定位算法,将算法应用到9个格子上,每个格子的输出为8维的,即

这与第一小节中的输出一样,如果一张图有两个对象,yolo算法的做法是取两个对象的中点,然后将这个对象分配到包含对象中点的格子。
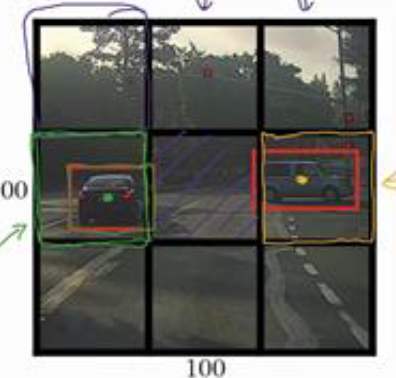
如上图所示的原图像,我们最终会得到 $3\times 3 \times 8$的输出,其中两个方框中有目标。
上述过程和图像定位和分类算法非常像,但是我们同时使用卷积实现上述步骤,就像第2小节讲的那样,所有的格子并行进行计算,许多步骤都是共享的,因此这个算法的效率很高,运行速度快,能够达到实时识别。
另外在Yolo算法中,每个方框中的左上角为(0,0),右下角为(1,1),如果有目标,中点肯定在这个方框中,因此$b_x$,$b_y$都在(0~1)区间中,但是高和宽却有可能在区间之外。
5. 交并比&非极大值抑制&Anchor Boxes
在目标检测实现后,我们需要有个指标评价目标检测算法的好坏,它就是交并比。
交并比(IoU)函数就是计算两个边界框交集和并集之比。
IOU:$(A\bigcap B) /(A \bigcup B)$
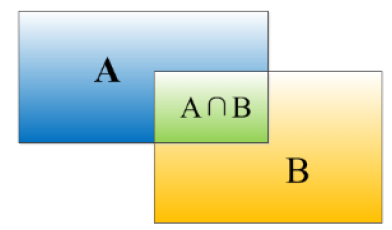
一般情况下,当IOU大于0.5时,我们就说检测正确,当然这个阈值可以变。
在我们的目标检测算法中,我们的算法有可能对一个对象作出多次检测,所以一个对象有可能有好几个框。

如上图所示,共有两个目标,由于格子很小,导致每个目标都有好几个格子认为自己是中心。非极大值抑制就是处理这个问题,使每个对象仅检测一次。
下面我们来看大致流程:
- 通过设置阈值排除出现目标概率比较小的方框
- 选择剩下方框中概率最高的
- 抛弃与步骤2中选择的方框IOU比较高的方框
- 重复处理步骤2、3
- 如果有多个对象,重复处理步骤2、3、4(注意,步骤2、3、4针对同一目标而言,例如汽车)
现在,我们的算法仍有缺陷,就是每个格子只能检测一个目标,如果一个格子中有多个目标,我们可以用anchor box实现。
它的方法是预定义两个不同形状的anchor box,我们需要把预测结果和这两个anchor box结合起来,当然,我们也可以使用更多的anchor box。
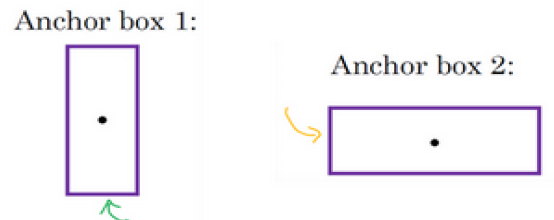
原来我们每个格子的类别标签为:
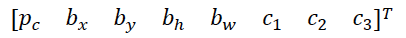
定义两个anchor box后,每个格子的类别标签为:

前面8个元素代表anchor box1的标签,后面8个元素代表anchor box2的标签。
因此我们的目标标签中,对于一个对象,我们存储的是(格子、anchor box)对。
我们的anchor box也会有一些缺陷:
- 当一个格子中的目标比anchor box的数量多。
- 两个对象分配到一个格子中,但是他们的anchor box形状一样。
当然,上述情况很少发生,特别是我们的格子比较小的时候。
关于anchor box我们可以预先设定;Yolo中有更好的做法,即使用k-means算法将两类对象形状聚类,用来来选择一组anchor box,这是自动选择anchor box的高级做法。
6. Yolo算法 & R-CNN
我们将上面的学习内容汇总在一起,就是Yolo算法的基本思想与流程,我们来具体看一下:
-
设定格子的数量n、anchor box的数量a和形状、需要检测对象的种类c
-
遍历所有格子,构造训练集以及标签
-
训练卷积网络,输出为$n \times n \times a \times (5+c)$
-
使用网络进行预测

-
对每个对象使用非极大值抑制

-
输出最终的矩阵
以上就是Yolo算法的主要流程,具体内容在前5小节已详细展开。
下面来看目标检测的另外一类算法,通过候选区域来进行目标检测。
我们之前提到的滑动窗口算法,会在所有的窗口内都运行一次网络,即使某个窗口什么也没有。
所以提出了带区域的卷积网络(R-CNN),意思是先尝试选出一些区域,然后使用卷积网络进行识别。
选出候选区域的方法就是使用图像分割算法,我们通过图像分割算法找出一些色块,然后在色块上放置边界框,然后再这些位置上运行分类器,比在图像的所有位置上放置分类器要快。
当然,R-CNN不会直接信任输入的边界框,他还是会重新输出边界框,这样得到的边界框更精确。
但是由于先取出候选区域,再进行图像分类,比较慢,因此提出了Fast R-CNN,他基本上是R-CNN算法,不过使用卷积实现了滑动窗口。
但是Fast R-CNN中的第一个步骤得到候选区域仍然非常慢,因此,提出了更快的R-CNN算法(Faster R-CNN),它使用卷积网络代替传统的分割算法来获得候选区域色块。这笔Fast R-CNN快很多,但是仍然比不上YOLO的速度。