1. 什么是词嵌入
在序列模型一章中,我们使用one-hot向量来表示词,这种表示方法的缺点就是它把每个词孤立起来,使得算法对相关词的泛化性不强。
为此,我们需要换一种表达方式,不使用one-hot表示,而是用特征化的表示来表示每一个词,我们学习词典中每个词的特征或者数值。
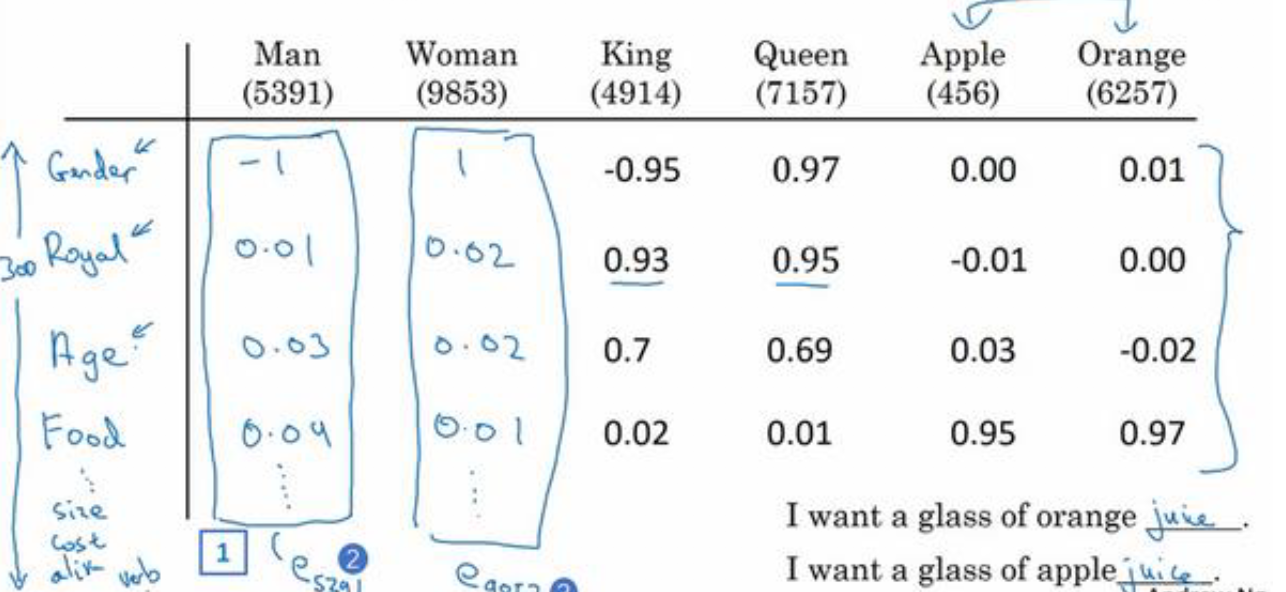
类似于上图这种方式,我们可以找到300个不同的特征,每个词汇在这300个特征是都使用不同的数字表示,这个每个词使用300维的向量表示,这样同种类的词汇就会有非常相似的特征。
通过这种方式让我们理解高维特征的表示能够比ont-hot更好的表示单词,词嵌入学习的特征能够使算法更高效的发现需要泛化的词语。
这种类似在300维空间中的表示方法叫做嵌入。
对于命名实体识别任务来说,如果测试样本中的词汇,没有出现我们的训练样本中,那么我们是不容易对新词汇进行预测的;但是使用词嵌入却有很好的泛化能力,它会根据训练集中的词汇,找出与其同类别的词汇,这样即使测试集中的词汇没有在训练集中出现,它也能通过泛化的方式进行预测。
词嵌入之所以能达到上述效果,其中一个原因是词嵌入算法会从非常大的文本集中训练,大量无标签的文本的训练集。
上述步骤实际上是用词嵌入做迁移学习,我们总结一下其步骤:
- 从大量文本集训练词嵌入,或者使用别人训练好的词嵌入模型。
- 将步骤1中的词嵌入模型,迁移到我们新的只有少量标注的训练集中的任务中。
- 在新的任务上训练模型,可以微调词嵌入,也可以不微调。
在NLP中,词嵌入效果比较明显的任务有:
- 命名实体识别
- 文本解析
- 指代消解
词嵌入使用较少的NLP任务(原本就有大量数据,不需要迁移):
- 语言模型
- 机器翻译
2. 类比推理
词嵌入的一个特性就是它能够帮助实现类比推理。
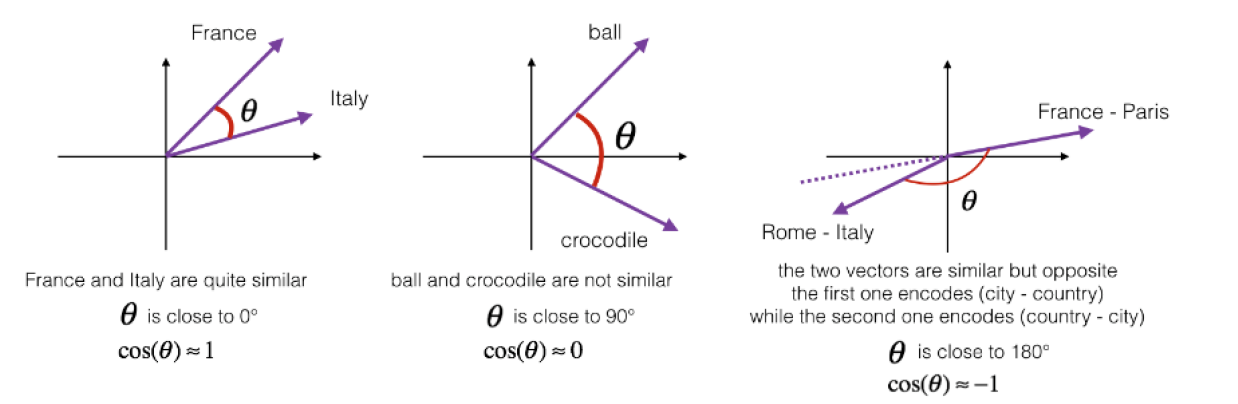
什么是类比推理,我们知道man对应woman,那么king对应什么?通过算法推导出King对应queue,这就是类比推理。
在一个300维的空间中,单词man、woman都是空间中的一个点,需要求解king对应的单词是什么,就要找到单词w,使得:
\[e_{man}-e_{woman}\approx e_{king}-e_w\tag{2-1}\]其实就是要找到单词,最大化$e_w$与$e_{king}-e_{man}+e_{woman}$的相似度。
这种方法做类比推理的准确率大概只有30%~75%之间。
上述过程只是简单的计算相似度,实际上有一个常用的计算相似度的函数:
- 余弦相似度
在向量u和v之间,我们计算相似度的公式为:
\[sim(u,v)=\frac{u^Tv}{\mid\mid u\mid\mid_2\mid\mid v\mid\mid_2}\tag{2-2}\]我们首先观察公式2-2的分子,实际上就是求内积,当两个向量很相似时,内积就会特别大,进而整个式子很大,相似度高。上式求取的实际上是$u$和$v$夹角的余弦值。
3. 词嵌入的实现(Word2Vec)
将词嵌入具体化时,实际上是具体化一个嵌入矩阵。
加入我们的词汇表中含有10000个单词,每个单词使用一个300维的向量表示,那么嵌入矩阵的形状为300 \times 10000,之前我们使用每个单词的one-hot的形状为10000 \times 1,将两者相乘即为300维的向量,表示当前单词的嵌入向量。
通过嵌入矩阵和one-hot向量相乘的方式,实际上是很耗资源的,我们在实际项目中,需要使用一个单独的函数快速的寻找到嵌入矩阵的某列。
了解了嵌入矩阵,我们首先学习一下复杂一些的算法,虽然有一些简单且效果更好的算法,但是都是从相对复杂的算法演化的,所以我们学习如何通过训练一个语言模型得到词嵌入。
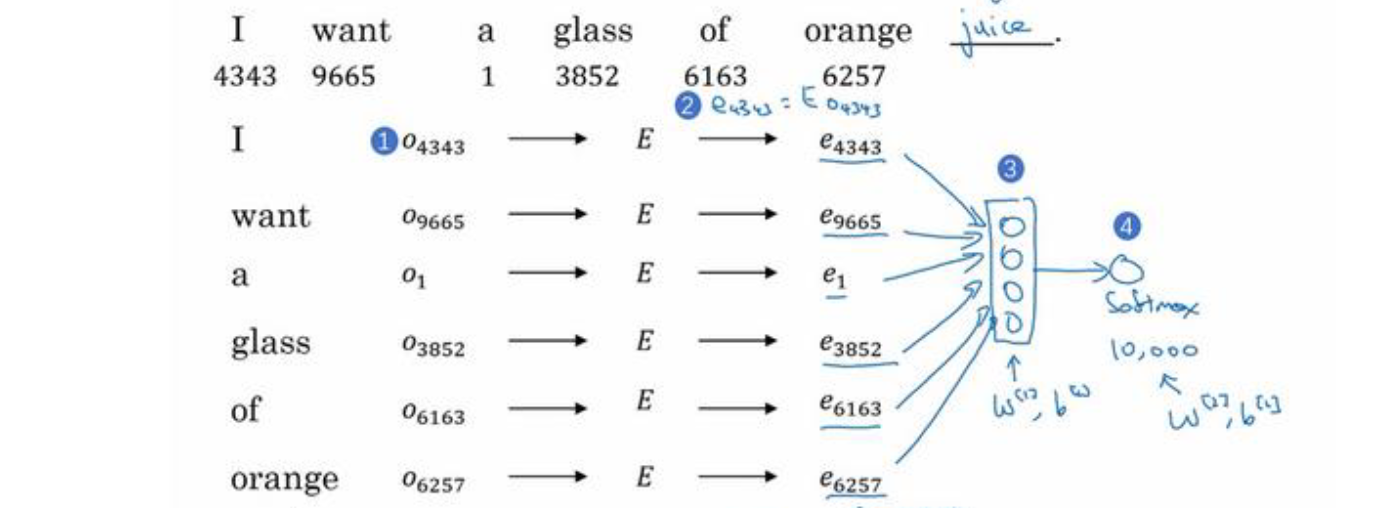
如上图所示,我们想要通过语言模型预测orange后面的单词,我们首先将包括orange的前面几个单词表示为one-hot向量,然后通过嵌入矩阵我们可以得到每个单词的词嵌入表示,将词嵌入作为输入,通过一个标准隐藏层,然后通过softmax得出所有单词的概率,即是语言模型的训练与预测过程。
在实际情况中,我们通常使用滑动窗口的方式,假如我们的滑动窗口大小为4,当我们训练上述语言模型时,只需要获取包含orange在内的前4个词就可以了,这样我们可以处理任意长的句子,因为我们输入的维度或者大小总是一样的。
注意,我们此时的网络的参数包括:嵌入矩阵、隐藏层权重等。
我们此时的目标是学习嵌入矩阵,也就是词嵌入,这样的话,我们可以选择不同的上下文,例如:
- 左面4个单词
- 后面4个单词
- 最有一个单词
- 最近的一个单词
如果我们的目标是获得一个很好的语言模型,那么获取目标词的前4个单词是作为上下文是一个很好的选择。
上面提到过,有一种简单却非常有效的算法,叫做Word2Vec我们现在来学习一下:
Word2Vec算法其中一个模型为Skip-Gram,具体流程为:抽取上下文和目标词配对,来构造监督学习问题。
我们首先随机选择一个词作为上下文词,然后在这个词的正负10个词或者正负5个词内,随机选择另一个词作为目标词。这样我们将构造一个监督学习问题,,这个监督学习问题的目标并不是问题本身,而是使用这个学习问题学习到一个好的词嵌入模型,即词嵌入矩阵。
我们的模型应该是下面这个样子:
\[O_c \rightarrow E \rightarrow e_c \rightarrow softmax \rightarrow \hat y \tag{3-1}\]公式3-1表示的是我们输入每个单词的one-hot向量,然后通过嵌入矩阵,计算得到词嵌入向量,再使用softmax处理词嵌入向量,最终得到预测的目标词结果。
其中,每个词预测大概率为(softmax函数的原理):
\[Softmax:p(t \mid c)=\frac{e^{\theta_t^Te_c}}{\sum_{j=1}^ne^{\theta_j^Te_c}}\tag{3-2}\]公式3-2就是通过softmax求得的目标词的概率。其中$\theta_t$是一个和输出t有关的参数,代表某个词t和标签相符的概率是多少。
损失函数就是softmax的损失函数:
\[L(\hat y,y)=- \sum_{i=1}^ny_ilog\hat y_i\tag{3-3}\]通过不断训练上述的监督学习问题,我们会得到很好的参数矩阵E,他就是我们的嵌入矩阵。
这是Skip-Gram模型,实际上还有另外一种模型:CBOW(连续词袋模型Continuous Bag-Of-Words Model),它获取中间词两边的上下文,然后预测中间的词。
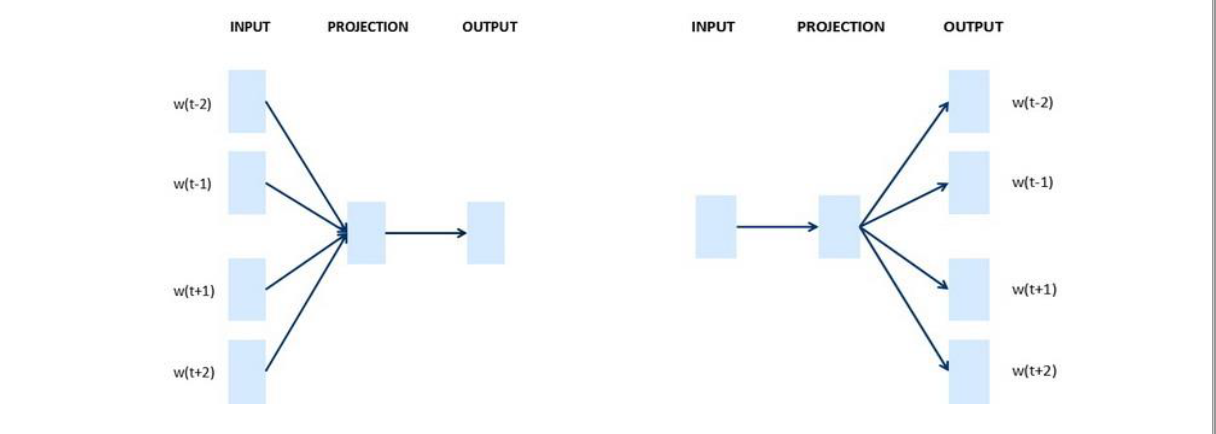
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
但是这个算法会遇到一些问题,其中比较严重的问题就是计算速度。我看观察公式3-2,公式的分母需要计算词汇表中所有词汇,然后做求和操作。解决方案有以下两种:
-
分级的softmax分类器
其实就是一个树形分类器,每个节点都是一个二分类器,这样我们就不需要计算词汇表中的全部参数求和了。
使用分级的softmax分类器,其计算成本与词汇表大小的对数成正比,而不是与词汇表大小成线性函数(不与词汇表大小成正比)
在实践中,我们不会使用平衡二叉树,或者说是左右相似的树。而是使用常用的词在顶部,不常用的词在深处的二叉树,因为我们希望常用的词很快能检索到。
-
负采样
构造一个新的监督学习问题:给定一对单词,我们需要预测这是否是一对上下文词-目标词。
我们首先随机采样一个上下文词,然后从一定间距内采样一个目标词,这一对上下文词-目标词的标签为1,作为正样本。
然后上下文词不变,从字典中随机选取词,与上下文词组成一个负样本,标签为0。
重复上述步骤k词,我们将得到一个正样本与k个负样本。
关于k的选择:如果是小训练集,K取大一点,5~20比较好;如果训练集比较大,K取小一点,2~5比较好。
我们详细看一下从x映射到y的监督模型:我们使用c代表上下文词,使用t代表目标词,使用y代表0和1,判断c与t是否是一对上下文词-目标词。我们的模型实际上是一个逻辑回归模型,即给定$c$与$t,y=1$的概率: \(P(y=1 \mid c,t)=\sigma(\theta^T_te_c)\tag{3-4}\) 在每次中,我们只使用k+1个样本进行训练,k指k个负样本,1指1个正样本。
其中的关键就是如何选取负样本,有以下几种方式:
-
通过词出现的频率进行采样,但是我们在the、of等词上有很高的频率
-
均匀且随机的选取负样本,但是对于英文单词的分布没有代表性
-
处于上述两种方法的中和,既不使用频率,也不是随机抽取,方式如下: \(P(W_i)=\frac{f(w_i)^{\frac{3}{4}}}{\sum_{j=1}^nf(w_j)^{\frac{3}{4}}}\tag{3-5}\) 通过$\frac{3}{4}$使其位于完全独立的分布(方法2)与观测到的频率(方法1)之间,许多研究者使用,发现效果不错。
-
另外一个比较简单的词嵌入算法是GloVa,代表用词表示的全局变量(global vectors for word representation),虽然不如Word2Vec使用的多,但是仍旧很多人喜爱。
假设$X_{ij}$表示单词$i$在单词$j$上下文中出现的次数,这里的$i$和$j$与$t$和$c$的功能一样,$X_{ij}$等于$X_{tc}$。
在GloVe算法中,可以定义上下文和目标词为任意两个位置相近的单词,例如左右各10次的距离,那么$X_{ij}$就表示一个能够获取单词$i$和单词$𝑗$出现位置相近时或是彼此接近的频率的计数器。
GloVe模型实际上做的是优化,将差距最小化处理:
\[minimize \;\sum_{i=1}^{n}\sum_{j=1}^nf(X_{ij})(\theta_i^Te_j+b_i+b_j'-\log X_{ij})^2\tag{4-1}\]我们使用梯度下降法对参数$\theta$和$e$进行学习,使得通过他们可以对两个词多紧密进行良好的预测。其中函数f的作用是加权项,在$X_{ij}=0$时求log的值时,可以使用f使后面的log为不相关项;还有就是对of、the这些词时,使用函数f停止运算;对于一些不常出现但是需要学习的词,我们可以增大f的权值等。
在这个模型中,$\theta$与$e$的作用就是完全一样的,因此他们是完全对称的。一种训练算法就是一致的初始化$\theta$与e,然后使用梯度下降法最小化公式4-1,最后对于一个单词$w$,我们取$e_w^{final}=\frac{\theta_w+e_w}{2}$。
4. 情感分类(Sentiment Classification)
情感分类就是根据一段文本判断是否喜爱讨论的东西,是NLP中的重要任务之一。
情感分类任务的挑战是标记的训练集没有那么多,但是通过使用词嵌入,即使我们的训练集没有那么多,也能得到效果不错的情感分类器。
我们直观的看一下任务:

情感分类问题的输入是一段文本,输出是我们要预测的相应情感,例如星级评价。
上面提到过,情感分类任务的训练集很少,但是通过使用词嵌入,在较少的训练集上仍能达到较好的效果。
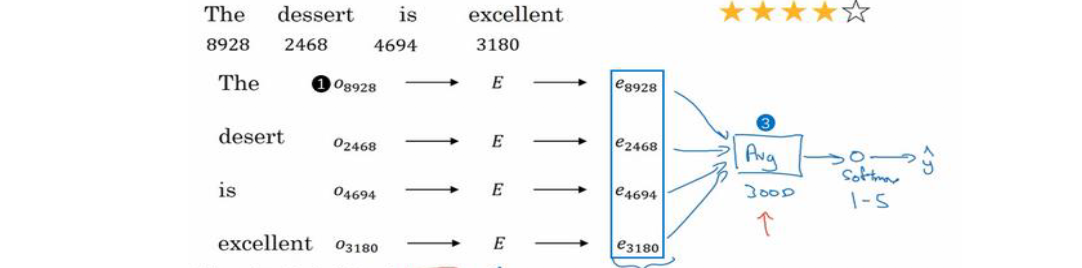
我们来学习几个情感分类的模型:
-
如上图所示,我们首先根据嵌入矩阵(提前从很大的数据集中学习到)与词汇表求出每个单词的词嵌入向量,然后取所有单词词嵌入向量的平均值,通过softmax进行分类。
这种方法适用于任意长度的评论,它将所有单词的意思平均起来。
但是没有考虑次序问题,例如评论中有一个否定词,但是没有考虑到,导致平均起来正面词居多。
-
第一种方法没考虑到词序问题,那么我们就会想到使用RNN,因此,我们可以获得一个更复杂的模型

如上图所示,与第一种方法不同,我们不对所有的词嵌入向量取平均,而是将它作为输入,放入RNN模型中,在RNN的最后一个时间步中,通过softmax选择类别。
这种方法弥补了方法1的缺陷,能够获取到词序信息。
以上两种方法都使用词嵌入,因为我们的嵌入矩阵是通过很大的训练集训练的,因此具有很好的泛化效果,即使在情感分类的训练集中没有出现某个单词,我们也可以通过词嵌入判断正确。
5. 词嵌入除偏
在我们学习的词嵌入中,有可能会存在很大的偏见,例如性别、种族、性取向等。实际上,这是对我们社会与经济的一个反应,但是在AI中,我们应该努力避免这些偏见。
下面我们来介绍一个方法,用来减少词嵌入中的偏见问题。
我们以性别歧视为例,这个方法需要下面3个例子:
-
识别偏见趋势
对于性别歧视,我们可以求$e_{he}-e_{she},e_{male}-e_{female}$的值,再求其差值,作为性别趋势或者偏见趋势。但是这个趋势与我们想要处理的特定偏见不相关,因此属于无偏见趋势。在这种情况下,偏见趋势可以看做1D的子空间,其余的299D空间为无偏见趋势。
当然,上面求差的操作实际上是一种简化做法,效果更佳好的做法是使用SVU,即奇异值分解。
-
中和步骤
我们仍以性别歧视为例,对于一些中性的词,例如doctor,babysitter,他们应该与称为性别中立的词,因此我们让他们在偏见趋势的1D子空间内位置相近,来消除性别歧视的成分。像grandmother、grandfather、girl、boy、she、he这些单词,我们就没必要进行中和,因为他们本来就与性别有关。
-
均衡步
在这一步中,我们要做的是对于某些与性别有关的词,我们只希望他们的不同点只在性别上,让他们具有一致的相似度。
例如grandfather与grandmother,我们希望他们与doctor与babysitter距离一样,因此,我们主要做的是将grandfather与grandmother移到与中轴线(性别偏见维度的中轴线)等距的一对点上。
在上面的三个步骤中,第2、3步其实是有问题的,问题在我们需要判断某个词是否属于性别趋势的(man、woman)还是中性的(doctor、babysitter),因此我们需要训练一个线性分类器告诉我们哪些词需要通过中和步骤消除性别偏见趋势,第3步中需要均衡的单词是很少的,与第2步分别处理了非中性词与中性词。